Les grands modèles de langage (GML) sont l’une des percées les plus marquantes en matière d’apprentissage automatique au cours des dernières années. Ils ont montré un potentiel pour automatiser des tâches auparavant impossibles, et un domaine où les GML excellent est le développement de logiciels. Cela a attiré l’attention des principales entreprises de technologie publique vers les entreprises en démarrage de premier niveau, ainsi que la communauté de logiciels à code source ouvert. Un des principaux efforts a été déployé par Princeton NLP Group avec SWE-agent. Il peut être considéré comme un ingénieur logiciel autonome qui débogue les bases de code existantes en tirant parti de modèles comme GPT-4.
Le 9 juillet 2024, Tower Research Ventures, en collaboration avec GenAI Collective, a coorganisé avec le Princeton NLP Group, qui a développé à la fois SWE-agent (un ingénieur logiciel autonome) et SWE-bench (un test de performance pour évaluer l’efficacité des agents), une soirée de conférences et de questions-réponses sur les applications de l’IA pour le développement logiciel autonome. Les participants comprenaient des chercheurs, des ingénieurs en apprentissage automatique, des fondateurs et d’autres praticiens.
Les conférences ont couvert des sujets allant des comparaisons entre les agents de génie logiciel à code source ouvert et à code source fermé à la pointe de la technologie à des appels pour des interfaces de calcul spécifiques aux agents, similaires aux besoins en interface utilisateur des développeurs de logiciels humains.

John Yang discute des paradigmes de génération d’agents
Des représentants de Princeton NLP ont fait la démonstration de SWE-agent, qui transforme les modèles de langage (ML) en agents capables de résoudre les bogues et les problèmes dans les référentiels GitHub. Ils ont expliqué son architecture de mise en œuvre et ont terminé avec la façon dont les praticiens peuvent modifier l’agent SWE. Lors de leur lancement en avril, leur approche était un système à code source ouvert à la pointe de la technologie avec un taux de résolution d’environ 12 %, tel qu’illustré dans la figure ci-dessous. L’agent SWE est devenu concurrentiel par rapport aux principales entreprises à code source fermé, dont l’une a un taux de résolution d’environ 14 %. Pour référence, les meilleures approches combinant RAG et modèles de base généralistes atteignent environ 4 %.
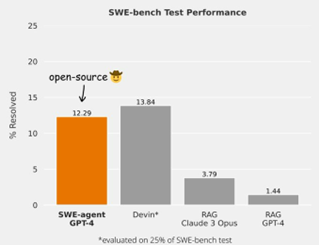
Source : Fil Twitter sur la performance de l’agent SWE.
Une autre discussion a couvert SWE-bench, un test de performance conçu pour évaluer la capacité des ML à résoudre des référentiels GitHub réels. Les chercheurs ont discuté des composants d’un bon test de performance : il doit être exigeant pour les modèles à la pointe de la technologie, refléter des cas d’utilisation réalistes, et offrir des évaluations de solutions claires. Ces critères les ont conduits à recueillir des instances de tests de performance en récupérant des paires de problèmes et de demandes de tirage avec des filtres tels que les tests de contribution. À partir du tableau de classement en ligne présenté le 9 juillet, on pouvait voir que les approches plus récentes des entreprises et des groupes de recherche surpassent désormais les performances de SWE-agent avec des[1] taux de résolution d’environ 19 %.

Kilian Lieberet passe en revue les détails de la mise en œuvre
Nous avons eu un excellent groupe d’ingénieurs présents, dont beaucoup ont partagé des visions ambitieuses sur ce à quoi ressemblera le développement logiciel autonome à l’avenir. Un grand merci au GenAI Collective pour avoir co-organisé l’événement!
Si vous travaillez dans ce domaine, nous serions ravis de discuter avec vous. Veuillez communiquer avec Tower Research Ventures à l’adresse ventures@tower-research.com!
[1]Taux en date du 9 juillet 2024. Notez que le tableau de nprd en ligne est mis à jour chaque semaine
Les opinions exprimées dans ce document sont uniquement celles de l’auteur (ou des auteurs), telles qu’elles étaient au moment de leur publication initiale, et ne reflètent pas nécessairement les opinions de Tower Research Ventures LLC ou de ses affiliés. Elles ne sont pas destinées à fournir, et ne doivent pas être considérées comme, des conseils en investissement, et aucune information contenue ici ne constitue une offre d’achat ou de vente de titres, ni ne doit être utilisée comme base pour l’achat ou la vente d’un investissement. Les informations contenues ici n’ont pas été et ne seront pas mises à jour ou révisées pour refléter les informations qui pourraient devenir disponibles ultérieurement, ni pour tenir compte des circonstances existantes ou des changements survenus après la date de préparation. Certaines informations contenues dans le présent document sont basées sur des sources publiées et non publiées. L’information n’a pas été vérifiée de façon indépendante par TRV ou ses représentants, et l’exactitude ou l’exhaustivité de ces renseignements n’est pas garantie. Votre lien vers ou utilisation de tout site Web tiers se fait à vos propres risques. Tower Research Ventures décline toute responsabilité quant aux produits ou services offerts ou aux renseignements contenus sur tout site Web tiers.